Model splitting for parallel and serial MODFLOW 6
The model splitting functionality for MODFLOW 6 is shown in this notebook. Model splitting via the Mf6Splitter() class can be performed on groundwater flow models as well as combined groundwater flow and transport models. The Mf6Splitter() class maps a model’s connectivity and then builds new models, with exchanges and movers between the new models, based on a user defined array of model numbers.
The Mf6Splitter() class supports Structured, Vertex, and Unstructured Grid models.
[1]:
import sys
from pathlib import Path
from shutil import copy, copytree
from tempfile import TemporaryDirectory
[2]:
import git
import matplotlib.pyplot as plt
import numpy as np
import pooch
import yaml
[3]:
import flopy
from flopy.mf6.utils import Mf6Splitter
from flopy.plot import styles
from flopy.utils.geometry import LineString, Polygon
Define a few utility functions.
[4]:
def string2geom(geostring, conversion=None):
if conversion is None:
multiplier = 1.0
else:
multiplier = float(conversion)
res = []
for line in geostring.split("\n"):
if not any(line):
continue
line = line.strip()
line = line.split(" ")
x = float(line[0]) * multiplier
y = float(line[1]) * multiplier
res.append((x, y))
return res
Create a temporary directory for this example.
[5]:
temp_dir = TemporaryDirectory()
workspace = Path(temp_dir.name)
Check if we are in the repository and define the data path.
[6]:
try:
root = Path(git.Repo(".", search_parent_directories=True).working_dir)
except:
root = None
[7]:
data_path = root / "examples" / "data" if root else Path.cwd()
Download and load geometries.
[8]:
geometries_fname = "geometries.yml"
geometries_fpath = pooch.retrieve(
url=f"https://github.com/modflowpy/flopy/raw/develop/examples/data/groundwater2023/{geometries_fname}",
fname=geometries_fname,
path=workspace,
known_hash="4fb491f9dbd09ef04d6d067458e9866ac79d96448f70910e78c552131a12b6be",
)
geometries = yaml.safe_load(open(geometries_fpath))
Downloading data from 'https://github.com/modflowpy/flopy/raw/develop/examples/data/groundwater2023/geometries.yml' to file '/tmp/tmp4wp8b3y6/geometries.yml'.
Download the Freyberg 1988 model.
[9]:
sim_name = "mf6-freyberg"
file_names = {
"bot.asc": "3107f907cb027460fd40ffc16cb797a78babb31988c7da326c9f500fba855b62",
"description.txt": "94093335eec6a24711f86d4d217ccd5a7716dd9e01cb6b732bc7757d41675c09",
"freyberg.cbc": "c8ad843b1da753eb58cf6c462ac782faf0ca433d6dcb067742d8bd698db271e3",
"freyberg.chd": "d8b8ada8d3978daea1758b315be983b5ca892efc7d69bf6b367ceec31e0dd156",
"freyberg.dis": "cac230a207cc8483693f7ba8ae29ce40c049036262eac4cebe17a4e2347a8b30",
"freyberg.dis.grb": "c8c26fb1fa4b210208134b286d895397cf4b3131f66e1d9dda76338502c7e96a",
"freyberg.hds": "926a06411ca658a89db6b5686f51ddeaf5b74ced81239cab1d43710411ba5f5b",
"freyberg.ic": "6efb56ee9cdd704b9a76fb9efd6dae750facc5426b828713f2d2cf8d35194120",
"freyberg.ims": "6dddae087d85417e3cdaa13e7b24165afb7f9575ab68586f3adb6c1b2d023781",
"freyberg.nam": "cee9b7b000fe35d2df26e878d09d465250a39504f87516c897e3fa14dcda081e",
"freyberg.npf": "81104d3546045fff0eddf5059465e560b83b492fa5a5acad1907ce18c2b9c15f",
"freyberg.oc": "c0715acd75eabcc42c8c47260a6c1abd6c784350983f7e2e6009ddde518b80b8",
"freyberg.rch": "a6ec1e0eda14fd2cdf618a5c0243a9caf82686c69242b783410d5abbcf971954",
"freyberg.riv": "a8cafc8c317cbe2acbb43e2f0cfe1188cb2277a7a174aeb6f3e6438013de8088",
"freyberg.sto": "74d748c2f0adfa0a32ee3f2912115c8f35b91011995b70c1ec6ae1c627242c41",
"freyberg.tdis": "9965cbb17caf5b865ea41a4ec04bcb695fe15a38cb539425fdc00abbae385cbe",
"freyberg.wel": "f19847de455598de52c05a4be745698c8cb589e5acfb0db6ab1f06ded5ff9310",
"k11.asc": "b6a8aa46ef17f7f096d338758ef46e32495eb9895b25d687540d676744f02af5",
"mfsim.nam": "6b8d6d7a56c52fb2bff884b3979e3d2201c8348b4bbfd2b6b9752863cbc9975e",
"top.asc": "3ad2b131671b9faca7f74c1dd2b2f41875ab0c15027764021a89f9c95dccaa6a",
}
for fname, fhash in file_names.items():
pooch.retrieve(
url=f"https://github.com/modflowpy/flopy/raw/develop/examples/data/{sim_name}/{fname}",
fname=fname,
path=data_path / sim_name,
known_hash=fhash,
)
[10]:
copytree(data_path / sim_name, workspace / sim_name)
[10]:
PosixPath('/tmp/tmp4wp8b3y6/mf6-freyberg')
Load the simulation, switch the workspace, and run the simulation.
[11]:
sim = flopy.mf6.MFSimulation.load(sim_ws=data_path / sim_name)
sim.set_sim_path(workspace / sim_name)
success, buff = sim.run_simulation(silent=True, report=True)
assert success, buff
loading simulation...
loading simulation name file...
loading tdis package...
loading model gwf6...
loading package dis...
loading package ic...
loading package oc...
loading package npf...
loading package sto...
loading package chd...
loading package riv...
loading package wel...
loading package rch...
loading solution package freyberg...
Visualize the head results and boundary conditions from this model.
[12]:
gwf = sim.get_model()
head = gwf.output.head().get_alldata()[-1]
[13]:
fig, ax = plt.subplots(figsize=(5, 7))
pmv = flopy.plot.PlotMapView(gwf, ax=ax)
heads = gwf.output.head().get_alldata()[-1]
heads = np.where(heads == 1e30, np.nan, heads)
vmin = np.nanmin(heads)
vmax = np.nanmax(heads)
pc = pmv.plot_array(heads, vmin=vmin, vmax=vmax)
pmv.plot_bc("WEL")
pmv.plot_bc("RIV", color="c")
pmv.plot_bc("CHD")
pmv.plot_grid()
pmv.plot_ibound()
plt.colorbar(pc)
[13]:
<matplotlib.colorbar.Colorbar at 0x7faf22d5e5f0>

Creating an array that defines the new models
In order to split models, the model domain must be discretized using unique model numbers. Any number of models can be created, however all of the cells within each model must be contiguous.
The Mf6Splitter() class accept arrays that are equal in size to the number of cells per layer (StructuredGrid and VertexGrid) or the number of model nodes (UnstructuredGrid).
In this example, the model is split diagonally into two model domains.
[14]:
modelgrid = gwf.modelgrid
[15]:
array = np.ones((modelgrid.nrow, modelgrid.ncol), dtype=int)
ncol = 1
for row in range(modelgrid.nrow):
if row != 0 and row % 2 == 0:
ncol += 1
array[row, ncol:] = 2
Plot the two domains that the model will be split into
[16]:
fig, ax = plt.subplots(figsize=(5, 7))
pmv = flopy.plot.PlotMapView(gwf, ax=ax)
pc = pmv.plot_array(array)
lc = pmv.plot_grid()
plt.colorbar(pc)
plt.show()
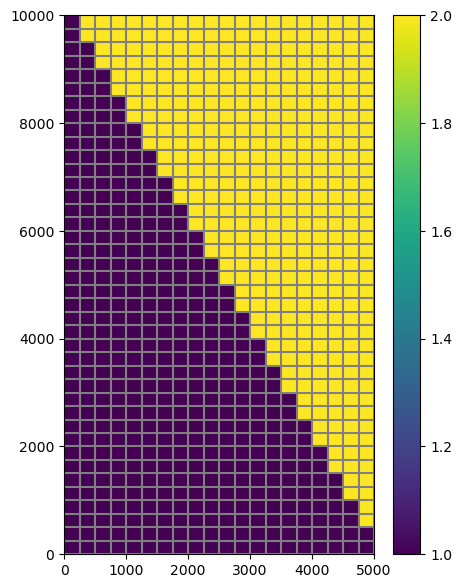
Splitting the model using Mf6Splitter()
The Mf6Splitter() class accepts one required parameter and one optional parameter. These parameters are:
sim: A flopy.mf6.MFSimulation objectmodelname: optional, the name of the model being split. If omitted Mf6Splitter grabs the first groundwater flow model listed in the simulation
[17]:
mfsplit = Mf6Splitter(sim)
The model splitting is then performed by calling the split_model() function. split_model() accepts an array that is either the same size as the number of cells per layer (StructuredGrid and VertexGrid) model or the number of nodes in the model (UnstructuredGrid).
This function returns a new MFSimulation object that contains the split models and exchanges between them
[18]:
new_sim = mfsplit.split_model(array)
[19]:
# now to write and run the simulation
new_sim.set_sim_path(workspace / "split_model")
new_sim.write_simulation()
success, buff = new_sim.run_simulation(silent=True)
assert success
writing simulation...
writing simulation name file...
writing simulation tdis package...
writing solution package ims_-1...
writing package freyberg_1_freyberg_2...
writing model freyberg_1...
writing model name file...
writing package dis...
writing package ic...
writing package oc...
writing package npf...
writing package sto...
writing package chd-1...
writing package riv-1...
writing package wel-1...
writing package rch-1...
writing model freyberg_2...
writing model name file...
writing package dis...
writing package ic...
writing package oc...
writing package npf...
writing package sto...
writing package riv-1...
writing package wel-1...
writing package rch-1...
Visualize and reassemble model output
Both models are visualized side by side
[20]:
# visualizing both models side by side
ml0 = new_sim.get_model("freyberg_1")
ml1 = new_sim.get_model("freyberg_2")
[21]:
heads0 = ml0.output.head().get_alldata()[-1]
heads1 = ml1.output.head().get_alldata()[-1]
[22]:
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(12, 7))
pmv = flopy.plot.PlotMapView(ml0, ax=ax0)
pmv.plot_array(heads0, vmin=vmin, vmax=vmax)
pmv.plot_ibound()
pmv.plot_grid()
pmv.plot_bc("WEL")
pmv.plot_bc("RIV", color="c")
pmv.plot_bc("CHD")
ax0.set_title("Model 0")
pmv = flopy.plot.PlotMapView(ml1, ax=ax1)
pc = pmv.plot_array(heads1, vmin=vmin, vmax=vmax)
pmv.plot_ibound()
pmv.plot_bc("WEL")
pmv.plot_bc("RIV", color="c")
pmv.plot_grid()
ax1.set_title("Model 1")
fig.subplots_adjust(right=0.8)
cbar_ax = fig.add_axes([0.85, 0.15, 0.05, 0.7])
cbar = fig.colorbar(pc, cax=cbar_ax, label="Hydraulic heads")

Array based model output can be assembled into the original model’s shape by using the reconstruct_array() method
reconstruct_array accepts a dictionary of array data. This data is assembled as {model_number: array_from_model}.
[23]:
array_dict = {1: heads0, 2: heads1}
[24]:
new_head_array = mfsplit.reconstruct_array(array_dict)
Recarray based model inputs and outputs can also be assembled into the original model’s shape by using the reconstruct_recarray() method
The code below demonstratess how to join the input recarrays for the WEL, RIV, and CHD package and plot them as boundary condition arrays.
[25]:
models = [ml0, ml1]
[26]:
pkgs = ["wel", "riv", "chd"]
d = {}
for pkg in pkgs:
rarrays = {}
for ix, model in enumerate(models):
pak = model.get_package(pkg)
try:
rarrays[ix + 1] = pak.stress_period_data.data[0]
except (TypeError, AttributeError):
pass
recarray = mfsplit.reconstruct_recarray(rarrays)
if pkg == "riv":
color = "c"
bc_array, kwargs = mfsplit.recarray_bc_array(recarray, color="c")
else:
bc_array, kwargs = mfsplit.recarray_bc_array(recarray, pkgtype=pkg)
d[pkg] = {"bc_array": bc_array, "kwargs": kwargs}
[27]:
fig, ax = plt.subplots(figsize=(5, 7))
pmv = flopy.plot.PlotMapView(gwf, ax=ax)
pc = pmv.plot_array(new_head_array, vmin=vmin, vmax=vmax)
pmv.plot_ibound()
pmv.plot_grid()
pmv.plot_array(d["wel"]["bc_array"], **d["wel"]["kwargs"])
pmv.plot_array(d["riv"]["bc_array"], **d["riv"]["kwargs"])
pmv.plot_array(d["chd"]["bc_array"], **d["chd"]["kwargs"])
plt.colorbar(pc)
plt.show()

Example 2: a more comprehensive example with the watershed model from Hughes and others 2023
In this example, a basin model is created and is split into many models. From Hughes, Joseph D., Langevin, Christian D., Paulinski, Scott R., Larsen, Joshua D., and Brakenhoff, David, 2023, FloPy Workflows for Creating Structured and Unstructured MODFLOW Models: Groundwater, https://doi.org/10.1111/gwat.13327
Create the model
Load an ASCII raster file
[28]:
ascii_file_name = "fine_topo.asc"
ascii_file = pooch.retrieve(
url=f"https://github.com/modflowpy/flopy/raw/develop/examples/data/geospatial/{ascii_file_name}",
fname=ascii_file_name,
path=data_path / "geospatial",
known_hash=None,
)
[29]:
copy(data_path / "geospatial" / ascii_file_name, workspace / ascii_file_name)
[29]:
PosixPath('/tmp/tmp4wp8b3y6/fine_topo.asc')
[30]:
fine_topo = flopy.utils.Raster.load(ascii_file)
fine_topo.plot()

[30]:
<Axes: >
[31]:
Lx = 180000
Ly = 100000
extent = (0, Lx, 0, Ly)
levels = np.arange(10, 110, 10)
vmin, vmax = 0.0, 100.0
[32]:
temp_dir = TemporaryDirectory()
workspace = Path(temp_dir.name)
[33]:
boundary_polygon = string2geom(geometries["boundary"])
boundary_polygon.append(boundary_polygon[0])
bp = np.array(boundary_polygon)
[34]:
# define stream segment locations
segs = [string2geom(geometries[f"streamseg{i}"]) for i in range(1, 5)]
Plot the model boundary and the individual stream segments for the RIV package
[35]:
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot()
ax.set_aspect("equal")
riv_colors = ("blue", "cyan", "green", "orange", "red")
ax.plot(bp[:, 0], bp[:, 1], "ro-")
for idx, seg in enumerate(segs):
sa = np.array(seg)
ax.plot(sa[:, 0], sa[:, 1], color=riv_colors[idx], lw=0.75, marker="o")

Create a MODFLOW model grid
[36]:
dx = dy = 5000
dv0 = 5.0
nlay = 1
nrow = int(Ly / dy) + 1
ncol = int(Lx / dx) + 1
delr = np.array(ncol * [dx])
delc = np.array(nrow * [dy])
top = np.ones((nrow, ncol)) * 1000.0
botm = np.ones((nlay, nrow, ncol)) * -100.0
modelgrid = flopy.discretization.StructuredGrid(
nlay=nlay, delr=delr, delc=delc, xoff=0, yoff=0, top=top, botm=botm
)
Crop the raster, resample it for the top elevation, and create an ibound array
[37]:
new_top = fine_topo.resample_to_grid(
modelgrid, band=fine_topo.bands[0], method="min", extrapolate_edges=True
)
[38]:
# calculate and set idomain
ix = flopy.utils.GridIntersect(modelgrid, rtree=True)
result = ix.intersect(Polygon(boundary_polygon), geo_dataframe=False)
idxs = tuple(zip(*result.cellids))
idomain = np.zeros((nrow, ncol), dtype=int)
idomain[idxs] = 1
[39]:
# set this idomain and top to the modelgrid
modelgrid._idomain = idomain
modelgrid._top = new_top
Intersect the stream segments with the modelgrid
[40]:
ixs = flopy.utils.GridIntersect(modelgrid)
cellids = []
for seg in segs:
v = ixs.intersect(LineString(seg), sort_by_cellid=True, geo_dataframe=False)
cellids += v["cellids"].tolist()
intersection_rg = np.zeros(modelgrid.shape[1:])
for loc in cellids:
intersection_rg[loc] = 1
[41]:
with styles.USGSMap():
fig, ax = plt.subplots(figsize=(8, 8))
pmv = flopy.plot.PlotMapView(modelgrid=modelgrid)
ax.set_aspect("equal")
pmv.plot_array(modelgrid.top)
pmv.plot_array(intersection_rg, masked_values=[0], alpha=0.2, cmap="Reds_r")
pmv.plot_inactive()
ax.plot(bp[:, 0], bp[:, 1], "r-")
for seg in segs:
sa = np.array(seg)
ax.plot(sa[:, 0], sa[:, 1], "b-")

Calculate drain conductance, set simulation options, and begin building model arrays
[42]:
# Set number of model layers to 2
nlay = 2
[43]:
# intersect stream segs to simulate as drains
ixs = flopy.utils.GridIntersect(modelgrid)
drn_cellids = []
drn_lengths = []
for seg in segs:
v = ixs.intersect(LineString(seg), sort_by_cellid=True, geo_dataframe=False)
drn_cellids += v["cellids"].tolist()
drn_lengths += v["lengths"].tolist()
[44]:
leakance = 1.0 / (0.5 * dv0) # kv / b
drn_data = []
for (r, c), length in zip(drn_cellids, drn_lengths):
x = modelgrid.xcellcenters[r, c]
width = 5.0 + (14.0 / Lx) * (Lx - x)
conductance = leakance * length * width
drn_data.append((0, r, c, modelgrid.top[r, c], conductance))
drn_data[:10]
[44]:
[(0,
np.int64(7),
np.int64(5),
np.float64(84.44444274902344),
np.float64(36308.337666948115)),
(0,
np.int64(8),
np.int64(5),
np.float64(84.44444274902344),
np.float64(2331.3467005764664)),
(0,
np.int64(8),
np.int64(6),
np.float64(81.66666412353516),
np.float64(33779.39187476463)),
(0,
np.int64(8),
np.int64(7),
np.float64(78.88888549804688),
np.float64(32345.996942392732)),
(0,
np.int64(8),
np.int64(8),
np.float64(76.11111450195312),
np.float64(31804.481845025493)),
(0,
np.int64(8),
np.int64(9),
np.float64(73.33333587646484),
np.float64(31019.952058682)),
(0,
np.int64(8),
np.int64(10),
np.float64(70.55555725097656),
np.float64(31812.20226149376)),
(0,
np.int64(8),
np.int64(11),
np.float64(70.0),
np.float64(818.127444214372)),
(0,
np.int64(9),
np.int64(11),
np.float64(67.77777862548828),
np.float64(33812.972572922656)),
(0,
np.int64(9),
np.int64(12),
np.float64(66.66666412353516),
np.float64(12528.002234921069))]
[45]:
# groundwater discharge to surface
idomain = modelgrid.idomain.copy()
index = tuple(zip(*drn_cellids))
idomain[index] = -1
gw_discharge_data = []
for r in range(nrow):
for c in range(ncol):
if idomain[r, c] < 1:
continue
conductance = leakance * dx * dy
gw_discharge_data.append((0, r, c, modelgrid.top[r, c] - 0.5, conductance, 1.0))
gw_discharge_data[:10]
[45]:
[(0, 1, 7, np.float64(99.99099731445312), 10000000.0, 1.0),
(0, 1, 8, np.float64(98.9864730834961), 10000000.0, 1.0),
(0, 1, 9, np.float64(97.68162536621094), 10000000.0, 1.0),
(0, 1, 10, np.float64(96.02616882324219), 10000000.0, 1.0),
(0, 1, 11, np.float64(93.93696594238281), 10000000.0, 1.0),
(0, 1, 12, np.float64(91.06060028076172), 10000000.0, 1.0),
(0, 1, 13, np.float64(87.65284729003906), 10000000.0, 1.0),
(0, 1, 14, np.float64(86.53125), 10000000.0, 1.0),
(0, 2, 5, np.float64(100.72657012939453), 10000000.0, 1.0),
(0, 2, 6, np.float64(100.33457946777344), 10000000.0, 1.0)]
[46]:
botm = np.zeros((nlay, nrow, ncol))
botm[0] = modelgrid.top - dv0
for ix in range(1, nlay):
dv0 *= 1.5
botm[ix] = botm[ix - 1] - dv0
[47]:
idomain = np.zeros((nlay, nrow, ncol), dtype=int)
idomain[:] = modelgrid.idomain
strt = np.zeros((nlay, nrow, ncol))
strt[:] = modelgrid.top
Create the watershed model using Flopy
[48]:
temp_dir = TemporaryDirectory()
workspace = Path(temp_dir.name) / "basin"
[49]:
sim = flopy.mf6.MFSimulation(
sim_name="basin",
sim_ws=workspace,
exe_name="mf6",
)
tdis = flopy.mf6.ModflowTdis(sim)
ims = flopy.mf6.ModflowIms(
sim,
complexity="simple",
print_option="SUMMARY",
linear_acceleration="bicgstab",
outer_maximum=1000,
inner_maximum=100,
outer_dvclose=1e-5,
inner_dvclose=1e-6,
)
gwf = flopy.mf6.ModflowGwf(
sim,
save_flows=True,
newtonoptions="NEWTON UNDER_RELAXATION",
)
dis = flopy.mf6.ModflowGwfdis(
gwf,
nlay=nlay,
nrow=nrow,
ncol=ncol,
delr=dx,
delc=dy,
idomain=idomain,
top=modelgrid.top,
botm=botm,
xorigin=0.0,
yorigin=0.0,
)
ic = flopy.mf6.ModflowGwfic(gwf, strt=strt)
npf = flopy.mf6.ModflowGwfnpf(
gwf,
save_specific_discharge=True,
icelltype=1,
k=1.0,
)
sto = flopy.mf6.ModflowGwfsto(
gwf,
iconvert=1,
ss=1e-5,
sy=0.2,
steady_state=True,
)
rch = flopy.mf6.ModflowGwfrcha(
gwf,
recharge=0.000001,
)
drn = flopy.mf6.ModflowGwfdrn(
gwf,
stress_period_data=drn_data,
pname="river",
)
drn_gwd = flopy.mf6.ModflowGwfdrn(
gwf,
auxiliary=["depth"],
auxdepthname="depth",
stress_period_data=gw_discharge_data,
pname="gwd",
)
oc = flopy.mf6.ModflowGwfoc(
gwf,
head_filerecord=f"{gwf.name}.hds",
budget_filerecord=f"{gwf.name}.cbc",
saverecord=[("HEAD", "ALL"), ("BUDGET", "ALL")],
printrecord=[("BUDGET", "ALL")],
)
[50]:
sim.write_simulation()
success, buff = sim.run_simulation(silent=True)
assert success
writing simulation...
writing simulation name file...
writing simulation tdis package...
writing solution package ims_-1...
writing model model...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
INFORMATION: maxbound in ('', 'drn', 'dimensions') changed to 88 based on size of stress_period_data
writing package gwd...
INFORMATION: maxbound in ('', 'drn', 'dimensions') changed to 470 based on size of stress_period_data
writing package oc...
Plot the model results
[51]:
water_table = flopy.utils.postprocessing.get_water_table(gwf.output.head().get_data())
heads = gwf.output.head().get_data()
hmin, hmax = water_table.min(), water_table.max()
contours = np.arange(0, 100, 10)
hmin, hmax
[51]:
(np.float64(1.1351828297118205), np.float64(105.96803703034477))
[52]:
with styles.USGSMap():
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot()
ax.set_xlim(0, Lx)
ax.set_ylim(0, Ly)
ax.set_aspect("equal")
pmv = flopy.plot.PlotMapView(modelgrid=gwf.modelgrid, ax=ax)
h = pmv.plot_array(heads, vmin=hmin, vmax=hmax)
c = pmv.contour_array(
water_table, levels=contours, colors="white", linewidths=0.75, linestyles=":"
)
plt.clabel(c, fontsize=8)
pmv.plot_inactive()
plt.colorbar(h, ax=ax, shrink=0.5)
ax.plot(bp[:, 0], bp[:, 1], "r-")
for seg in segs:
sa = np.array(seg)
ax.plot(sa[:, 0], sa[:, 1], "b-")

Split the watershed model
Build a splitting array and split this model into many models for parallel modflow runs
[53]:
nrow_blocks, ncol_blocks = 2, 4
row_inc, col_inc = int(nrow / nrow_blocks), int(ncol / ncol_blocks)
row_inc, col_inc
[53]:
(10, 9)
[54]:
icnt = 0
row_blocks = [icnt]
for i in range(nrow_blocks):
icnt += row_inc
row_blocks.append(icnt)
if row_blocks[-1] < nrow:
row_blocks[-1] = nrow
row_blocks
[54]:
[0, 10, 21]
[55]:
icnt = 0
col_blocks = [icnt]
for i in range(ncol_blocks):
icnt += col_inc
col_blocks.append(icnt)
if col_blocks[-1] < ncol:
col_blocks[-1] = ncol
col_blocks
[55]:
[0, 9, 18, 27, 37]
[56]:
mask = np.zeros((nrow, ncol), dtype=int)
[57]:
# create masking array
ival = 1
model_row_col_offset = {}
for idx in range(len(row_blocks) - 1):
for jdx in range(len(col_blocks) - 1):
mask[
row_blocks[idx] : row_blocks[idx + 1],
col_blocks[jdx] : col_blocks[jdx + 1],
] = ival
model_row_col_offset[ival - 1] = (row_blocks[idx], col_blocks[jdx])
# increment model number
ival += 1
[58]:
plt.imshow(mask)
[58]:
<matplotlib.image.AxesImage at 0x7faf0d2a6590>

Now split the model into many models using Mf6Splitter()
[59]:
mfsplit = Mf6Splitter(sim)
new_sim = mfsplit.split_model(mask)
[60]:
new_ws = workspace / "split_models"
new_sim.set_sim_path(new_ws)
new_sim.write_simulation()
success, buff = new_sim.run_simulation(silent=True)
assert success
writing simulation...
writing simulation name file...
writing simulation tdis package...
writing solution package ims_-1...
writing package model_1_model_2...
writing package model_1_model_5...
writing package model_2_model_3...
writing package model_2_model_6...
writing package model_3_model_4...
writing package model_3_model_7...
writing package model_4_model_8...
writing package model_5_model_6...
writing package model_6_model_7...
writing package model_7_model_8...
writing model model_1...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_2...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_3...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_4...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package gwd...
writing package oc...
writing model model_5...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_6...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_7...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_8...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
Reassemble the heads to the original model shape for plotting
Create a dictionary of model number : heads and use the reconstruct_array() method to get a numpy array that is the original shape of the unsplit model.
[61]:
model_names = list(new_sim.model_names)
head_dict = {}
for modelname in model_names:
mnum = int(modelname.split("_")[-1])
head = new_sim.get_model(modelname).output.head().get_alldata()[-1]
head_dict[mnum] = head
[62]:
ra_heads = mfsplit.reconstruct_array(head_dict)
ra_watertable = flopy.utils.postprocessing.get_water_table(ra_heads)
[63]:
with styles.USGSMap():
fig, axs = plt.subplots(nrows=3, figsize=(8, 12))
diff = ra_heads - heads
hv = [ra_heads, heads, diff]
titles = ["Multiple models", "Single model", "Multiple - single"]
for idx, ax in enumerate(axs):
ax.set_aspect("equal")
ax.set_title(titles[idx])
if idx < 2:
levels = contours
vmin = hmin
vmax = hmax
else:
levels = None
vmin = None
vmax = None
pmv = flopy.plot.PlotMapView(modelgrid=gwf.modelgrid, ax=ax, layer=0)
h = pmv.plot_array(hv[idx], vmin=vmin, vmax=vmax)
if levels is not None:
c = pmv.contour_array(
hv[idx], levels=levels, colors="white", linewidths=0.75, linestyles=":"
)
plt.clabel(c, fontsize=8)
pmv.plot_inactive()
plt.colorbar(h, ax=ax, shrink=0.5)
ax.plot(bp[:, 0], bp[:, 1], "r-")
for seg in segs:
sa = np.array(seg)
ax.plot(sa[:, 0], sa[:, 1], "b-")

Example 3: create an optimized splitting mask for a model
In the previous examples, the watershed model splitting mask was defined by the user. Mf6Splitter also has a method called optimize_splitting_mask that creates a mask based on the number of models the user would like to generate.
The optimize_splitting_mask() method generates a vertex weighted adjacency graph, based on the number active and inactive nodes in all layers of the model. This adjacency graph is then provided to pymetis which does the work for us and returns a membership array for each node.
[64]:
# Split the watershed model into many models
mfsplit = Mf6Splitter(sim)
split_array = mfsplit.optimize_splitting_mask(nparts=8)
with styles.USGSMap():
fig, ax = plt.subplots(figsize=(12, 8))
pmv = flopy.plot.PlotMapView(gwf, ax=ax)
pmv.plot_array(split_array)
pmv.plot_inactive()
pmv.plot_grid()

[65]:
new_sim = mfsplit.split_model(split_array)
temp_dir = TemporaryDirectory()
workspace = Path(temp_dir.name)
new_ws = workspace / "opt_split_models"
new_sim.set_sim_path(new_ws)
new_sim.write_simulation()
success, buff = new_sim.run_simulation(silent=True)
assert success
writing simulation...
writing simulation name file...
writing simulation tdis package...
writing solution package ims_-1...
writing package model_0_model_1...
writing package model_0_model_3...
writing package model_0_model_5...
writing package model_0_model_7...
writing package model_1_model_2...
writing package model_1_model_3...
writing package model_1_model_5...
writing package model_2_model_3...
writing package model_4_model_5...
writing package model_4_model_6...
writing package model_5_model_7...
writing package model_6_model_7...
writing model model_0...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_1...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_2...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_3...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_4...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_5...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_6...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
writing model model_7...
writing model name file...
writing package dis...
writing package ic...
writing package npf...
writing package sto...
writing package rcha_0...
writing package river...
writing package gwd...
writing package oc...
Reassemble the heads and plot results
[66]:
model_names = list(new_sim.model_names)
head_dict = {}
for modelname in model_names:
mnum = int(modelname.split("_")[-1])
head = new_sim.get_model(modelname).output.head().get_alldata()[-1]
head_dict[mnum] = head
[67]:
ra_heads = mfsplit.reconstruct_array(head_dict)
ra_watertable = flopy.utils.postprocessing.get_water_table(ra_heads)
[68]:
with styles.USGSMap():
fig, axs = plt.subplots(nrows=3, figsize=(8, 12))
diff = ra_heads - heads
hv = [ra_heads, heads, diff]
titles = ["Multiple models", "Single model", "Multiple - single"]
for idx, ax in enumerate(axs):
ax.set_aspect("equal")
ax.set_title(titles[idx])
if idx < 2:
levels = contours
vmin = hmin
vmax = hmax
else:
levels = None
vmin = None
vmax = None
pmv = flopy.plot.PlotMapView(modelgrid=gwf.modelgrid, ax=ax, layer=0)
h = pmv.plot_array(hv[idx], vmin=vmin, vmax=vmax)
if levels is not None:
c = pmv.contour_array(
hv[idx], levels=levels, colors="white", linewidths=0.75, linestyles=":"
)
plt.clabel(c, fontsize=8)
pmv.plot_inactive()
plt.colorbar(h, ax=ax, shrink=0.5)
ax.plot(bp[:, 0], bp[:, 1], "r-")
for seg in segs:
sa = np.array(seg)
ax.plot(sa[:, 0], sa[:, 1], "b-")

Save node mapping data
The save_node_mapping() method allows users to save a HDF5 representation of model splitter information that can be reloaded and used to reconstruct arrays at a later time
[69]:
filename = workspace / "node_mapping.hdf5"
mfsplit.save_node_mapping(filename)
reloading node mapping data
The load_node_mapping() method allows the user to instantiate a Mf6Splitter object from a hdf5 node mapping file for reconstructing output arrays
[70]:
mfs = Mf6Splitter.load_node_mapping(filename)
Reconstruct heads using the Mf6Splitter object we just created
[71]:
model_names = list(new_sim.model_names)
head_dict = {}
for modelname in model_names:
mnum = int(modelname.split("_")[-1])
head = new_sim.get_model(modelname).output.head().get_alldata()[-1]
head_dict[mnum] = head
ra_heads = mfs.reconstruct_array(head_dict)
ra_watertable = flopy.utils.postprocessing.get_water_table(ra_heads)
[72]:
with styles.USGSMap():
fig, axs = plt.subplots(nrows=3, figsize=(8, 12))
diff = ra_heads - heads
hv = [ra_heads, heads, diff]
titles = ["Multiple models", "Single model", "Multiple - single"]
for idx, ax in enumerate(axs):
ax.set_aspect("equal")
ax.set_title(titles[idx])
if idx < 2:
levels = contours
vmin = hmin
vmax = hmax
else:
levels = None
vmin = None
vmax = None
pmv = flopy.plot.PlotMapView(modelgrid=gwf.modelgrid, ax=ax, layer=0)
h = pmv.plot_array(hv[idx], vmin=vmin, vmax=vmax)
if levels is not None:
c = pmv.contour_array(
hv[idx], levels=levels, colors="white", linewidths=0.75, linestyles=":"
)
plt.clabel(c, fontsize=8)
pmv.plot_inactive()
plt.colorbar(h, ax=ax, shrink=0.5)
ax.plot(bp[:, 0], bp[:, 1], "r-")
for seg in segs:
sa = np.array(seg)
ax.plot(sa[:, 0], sa[:, 1], "b-")
